Kandinsky 3.1: искусство, созданное словами
Введение
2023 год можно смело называть годом бурного развития генеративного искусственного интеллекта. Это касается не только привычной нам модальности изображений (Kandinsky 2.1, 2.2, 3.0, Stable Diffusion XL, IF, Шедеврум и др.), но и текстовой (ChatGPT, GPT-4, LLaMA, Falcon, GigaChat и др.), аудио (VALL-E, MusicLM и др.), 3D (Magic3D и др.), и даже модальности видео (Kandinsky Video, Gen-2, CogVideo и др.). В 2024 всё движется ещё более впечатляющими темпами: картинки (SD3), видео (Sora), музыка (Suno) и т. д. При этом все основные игроки стараются равномерно двигаться вперёд и повышать качество синтеза. Текстовые чат‑боты научились взаимодействовать с внешними системами посредством плагинов, синтез изображений вышел на уровень фотореалистичных генераций, длина генерируемых видео постепенно увеличивается с сохранением сюжетной связности между кадрами. И такой прогресс обусловлен уже не только наращиванием вычислительных мощностей, но и большим числом неординарных архитектурных решений, которые позволяют добиваться лучшего качества, а также сложными технологиями инженерии данных, позволяющими создавать огромные и в то же время очень качественные наборы данных для обучения моделей.
В ноябре прошлого года, на конференции AI Journey, наша команда также представила новое поколение text-to-image-модели Kandinsky 3.0. В целом упростив архитектуру и взяв более мощный текстовый кодировщик по сравнению с семейством моделей Kandinsky 2.x, нам удалось добиться значительного роста в качестве изображений с точки зрения реалистичности и детализации, улучшить понимание текста и побить качество модели SDXL на side-by-side-сравнении с точки зрения человеческих предпочтений, что является наиболее показательной метрикой качества в задаче генерации. Подробнее о модели Kandinsky 3.0 можно прочитать в этой статье статье. Также, на базе этой модели в том же ноябре мы выпустили первую российскую модель генерации видео по тексту Kandinsky Video, о которой можно больше узнать здесь.
Сегодня мы представляем модель Kandinsky 3.1 — идейное продолжение модели Kandinsky 3.0, которую мы улучшили и обогатили набором различных полезных функций и режимов для того, чтобы предоставить пользователям больше возможностей полноценно использовать всю силу нашей новой модели. В этой статье мы опишем ключевые изменения, которые мы внесли в нашу модель.
Ускорение модели
Серьезной проблемой модели Kandinsky 3.0, как и всех диффузионных моделей, была скорость генерации. Для получения одного изображения было необходимо пройти 50 шагов в обратном процессе диффузии, то есть 50 раз пропустить данные через U-Net с размером батча 2 для classifier free guidance. Для решения этой проблемы мы использовали подход Adversarial Diffusion Distillation, впервые описанный в статье от Stability AI, но с рядом существенных модификаций:
В случае использования предобученных пиксельных моделей в качестве дискриминатора, возникла бы необходимость декодировать сгенерированную картинку при помощи MoVQ и пробрасывать через него градиенты, что привело бы к огромных затратам памяти. Данные затраты не позволяют обучать модель в разрешении 1024 × 1024. Поэтому в качестве дискриминатора мы использовали замороженную downsample-часть U-Net от Kandinsky 3.0 с обучаемыми головами после каждого слоя понижения разрешения. Это связано с желанием сохранить возможность генерировать картинки в высоком разрешении.
Мы добавили Cross Attention на текстовые эмбеддинги от FLAN-UL2 в головы дискриминатора вместо добавления текстового CLIP эмбеддинга. Это позволило улучшить понимание текста дистиллированной моделью.
В качестве лосс функции мы использовали Wasserstein Loss. В отличие от Hinge Loss он является ненасыщаемым, что позволяет избежать проблемы зануления градиентов на первых этапах обучения, когда дискриминатор оказывается сильнее генератора.
Мы убрали регуляризацию в виде Distillation Loss, так как по нашим экспериментам она не оказывала влияние на качество модели.
Мы обнаружили, что довольно быстро генератор становится сильнее дискриминатора, что приводит к нестабильности обучения. Чтобы решить эту проблему мы значительно увеличили learning rate у дискриминатора. У дискриминатора он равнялся 1e-3, в то время как у генератор 1e-5. Для предотвращения расходимости мы также использовали gradient penalty, как и в оригинальной работе.

Обучение происходило на эстетическом датасете размером 100 тысяч пар изображений-текст, который является подсетом датасета для претрейна Kandinsky 3.0.
В результате этого подхода получилось ускорить Kandinsky 3.0 почти в 20 раз, сделав возможным генерировать изображение за всего 4 прохода через U-Net. Также на скорость повлиял тот факт, что теперь нет необходимости использовать classifier free guidance. Kandinsky 3.0 из диффузионной модели по факту превратился в GAN, обученный с хорошей начальной инициализацией весов после претрейна.
Однако за серьёзное ускорение пришлось пожертвовать качеством понимания текста, что показывают результаты side-by-side сравнения.
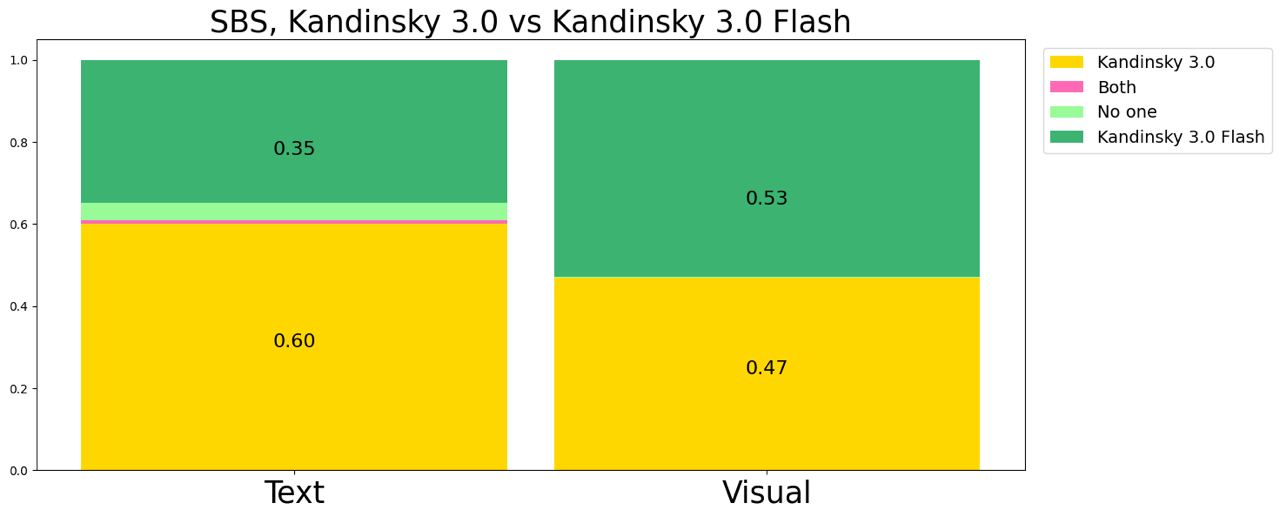
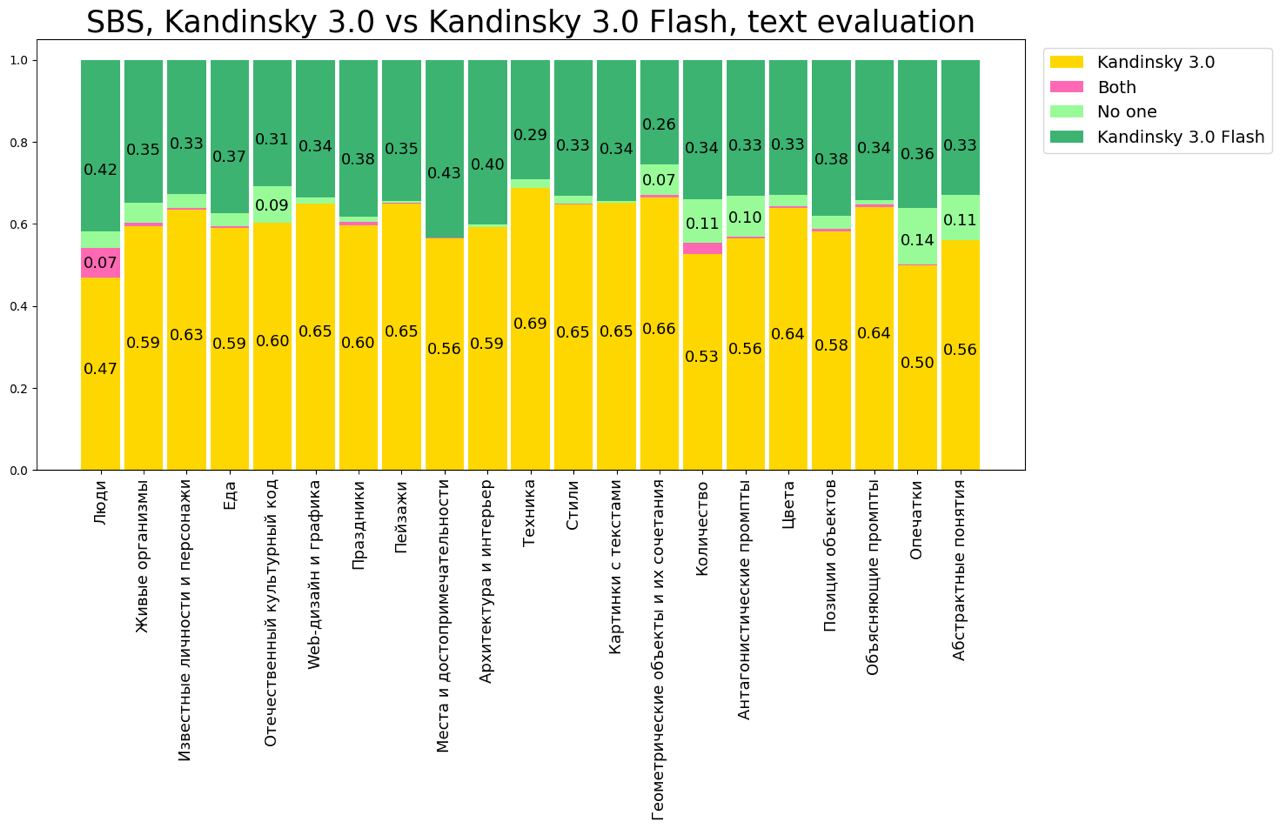
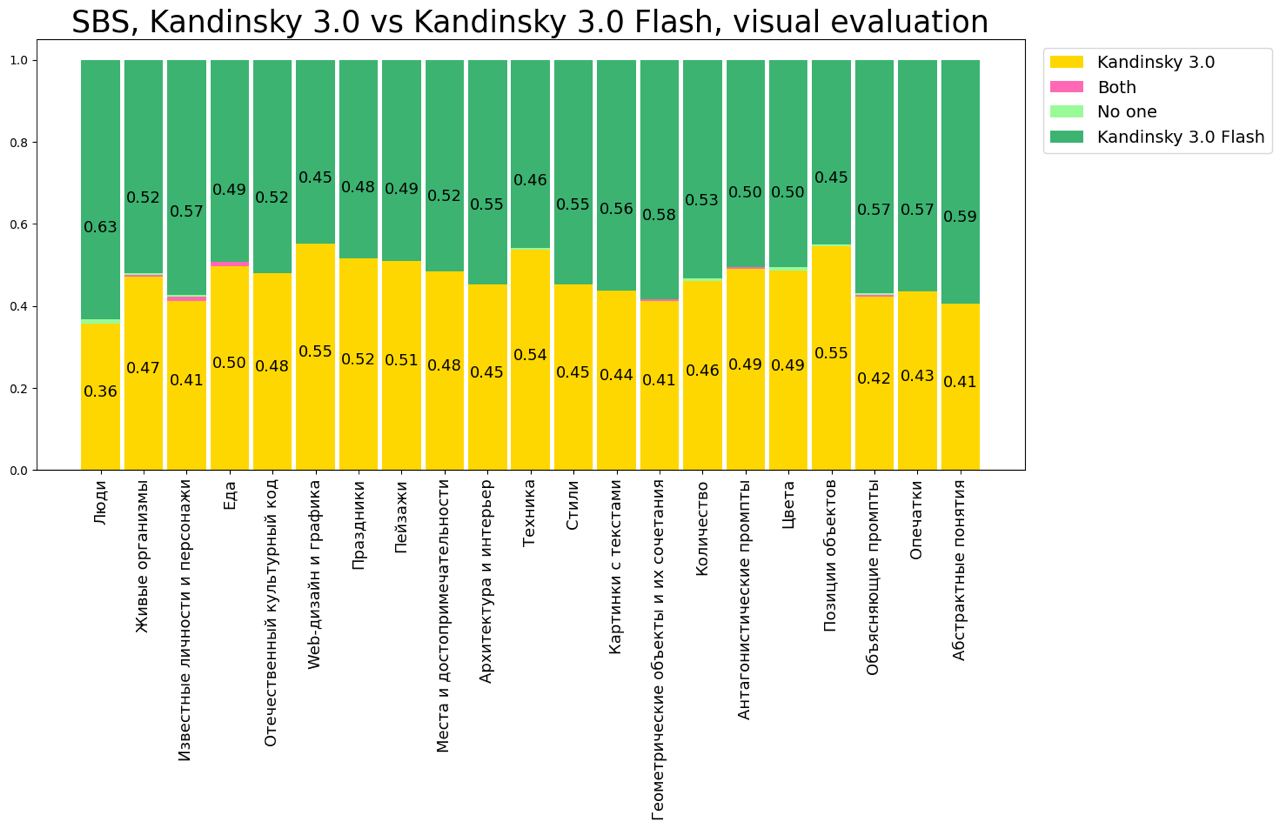

Сравнение Kandinsky 3.1 с предыдущими версиями:




Сравнение Kandinsky 3.1 с другими моделями:






Эволюция моделей Kandinsky:



Бьютификация запроса
Если вы пользовались прошлыми версиями Kandinsky или другими картиночными генеративными моделями, то скорее всего заметили, что чем подробнее напишите запрос, тем красивее и детальнее получится картинка. Однако, большинство запросов пользователей очень короткие и содержат мало подробностей об объекте генерации. Не у всех пользователей есть время долго подбирать нужный им промпт — в большинстве случаев достаточно получить просто красивую генерацию по введенному запросу.
Для решения этой проблемы была встроена функция бьютификации запроса — способ улучшения и добавления деталей к запросу пользователя с помощью большой языковой модели (LLM). Бьютификация работает очень просто: на вход языковой модели подаётся инструкция с просьбой улучшить запрос, и ответ модели подается на вход Kandinsky для генерации.
В качестве LLM мы использовали neural-chat-7b-v3-1 от Intel со следующим системным промтом:
### System:\nYou are a prompt engineer. Your mission is to expand prompts written by user. You should provide the best prompt for text to image generation in English. \n### User:\n{prompt}\n### Assistant:\n
Тут {prompt} — это запрос, который написал пользователь.
Примеры генераций на один и тот же запрос, но с бьютификацией и без нее представлены ниже.



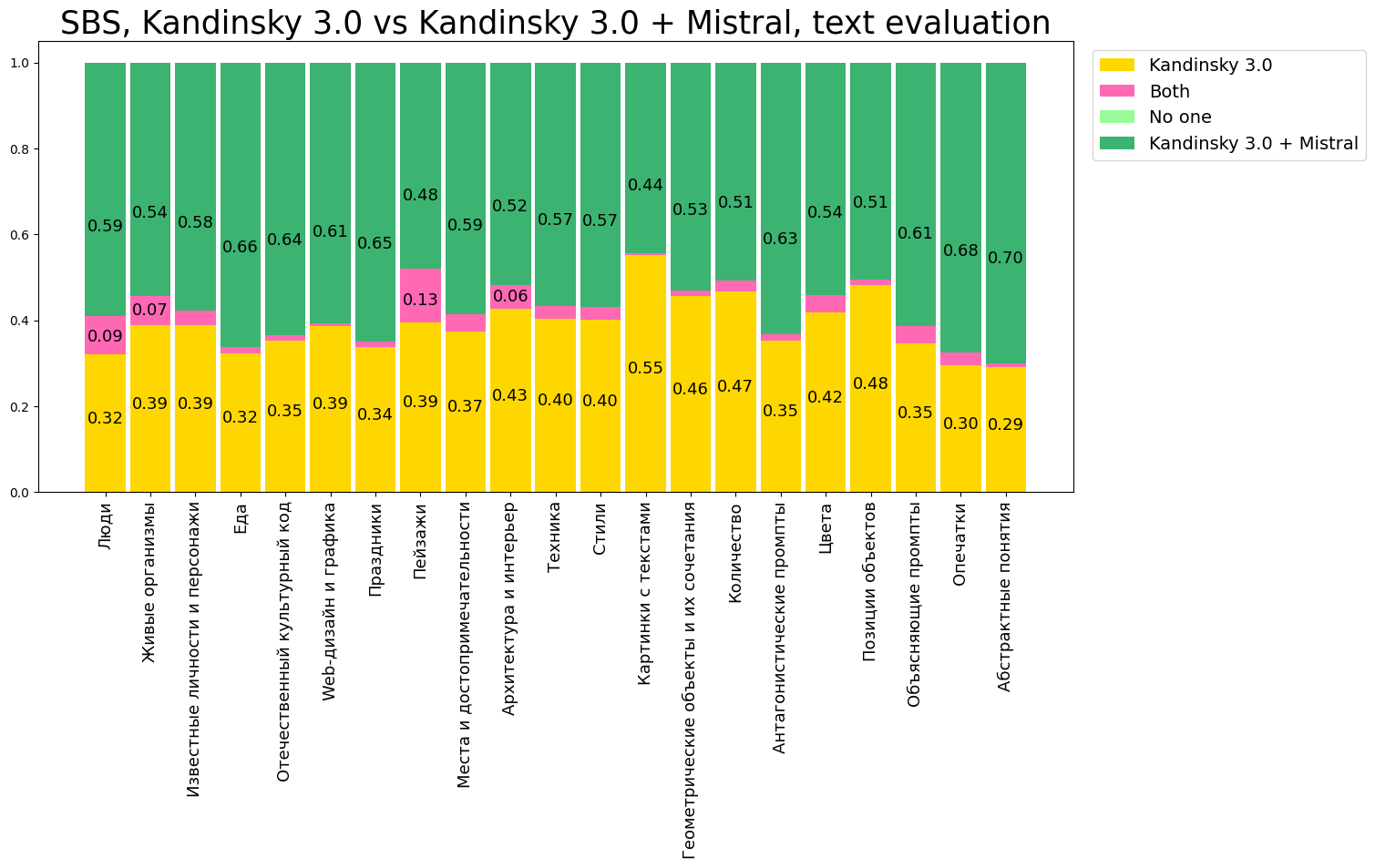
Также мы провели side-by-side сравнение качества генераций, сделанных Kandinsky с использованием функции бьютификации запроса и без него. Мы провели тестирование и для Kandinsky 3.0, и для Kandinsky 3.1, чтобы оценить как сильно влияет языковая модель на генерируемые изображения. SBS проводится на фиксированной корзине запросов. Каждая генерация оценивается по визуальному качеству (какое из двух изображений вам больше нравится) и по соответствию тексту (какое из двух изображений лучше соответствует запросу).
Результаты SBS для модели Kandinsky 3.0:
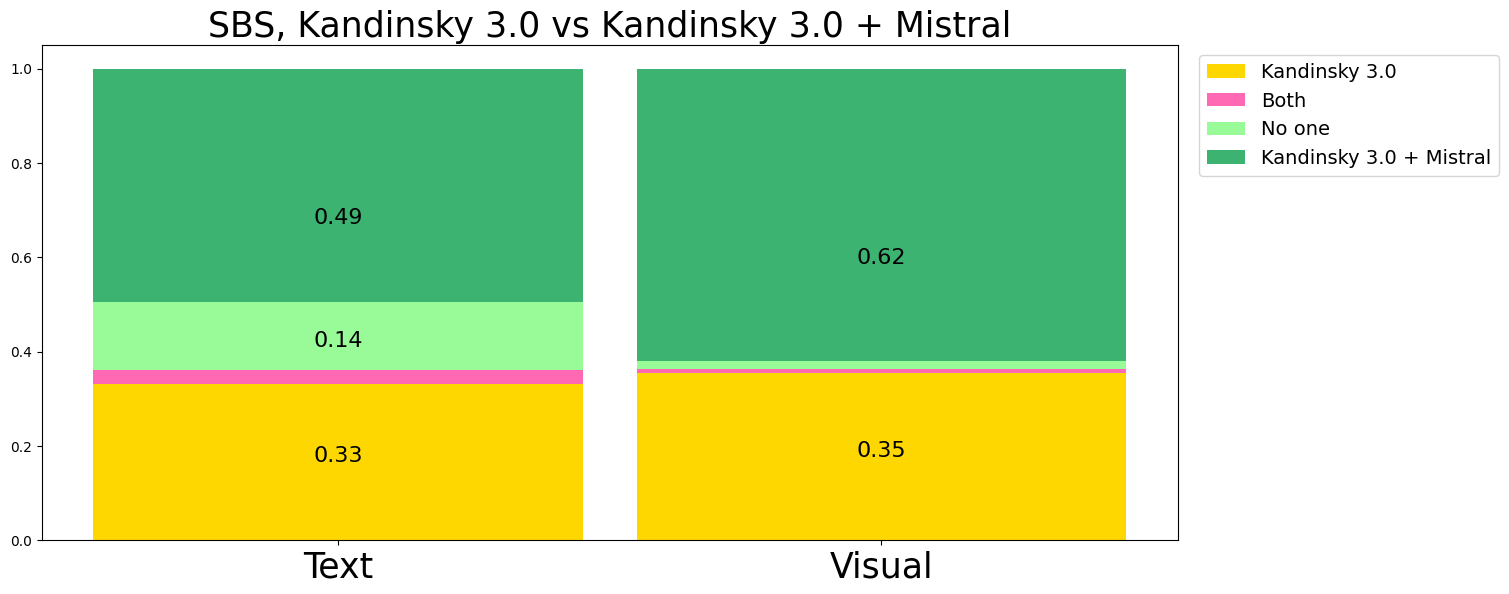


Редактирование изображений и Text-Image Guidance
По сравнению с моделью Kandinsky 3.0, в версию 3.1 мы внедрили функционал генерации изображения не только с помощью текстового запроса, но и/или с помощью визуальной подсказки в виде подаваемого на вход изображения. Это позволяет редактировать уже имеющееся изображение, изменять его стиль и добавлять к нему новые объекты. Для этого мы использовали IP-Adapter — подход, продемонстрировавший хорошие результаты в сравнении с традиционным дообучением.
Для реализации IP-Adapter-а на основе нашей базовой модели генерации и её имплементации в библиотеке diffusers мы использовали адаптеры внимания. В качестве модели CLIP мы использовали ViT-L/14. С его помощью мы получаем эмбеддинги размера batch_size x 768, которые потом, посредством линейного слоя, преобразуются в тензоры размером batch_size × 4 × 4096. Добавив пару новых слоев для key и value изображений в механизме cross attention, мы складываем выход обычного текстового cross attention с выходом cross attention для изображений. Обучение производилось на датасете COYO 700m с размером батча 288 в течение 800 тысяч итераций.
Поддерживаемые варианты инференса:
Вариация изображения. Чтобы сделать вариацию изображения мы просто считаем эмбеддинги изображения с помощью CLIP и подаем их в модель.

Смешивание изображений. Здесь мы считаем эмбеддинги для каждого изображения и складываем их с заданными весами, после чего результат подается в модель.

Смешивание изображения и текста. Мы считаем эмбеддинги изображения и подаем их в модель вместе с текстом, поскольку мы сохранили стандартный cross attention на текст.


Редактирование в режиме ControlNet
Мы обнаружили, что подход на основе IP-адаптера не сохраняет форму объектов на изображении, поэтому мы решили обучить ControlNet в дополнении к нашей модели генерации для консистентного изменения внешнего вида изображения, сохраняющего больше информации в сравнении с исходным. В качестве модели для получения границ на изображении, подающихся на вход ControlNet, мы использовали HED detector. Обучение длилось 5 тысяч итераций на датасете COYO 700m на 8 GPU Tesla A100 с размером батча 512.
Inpainting
В Kandinsky 3.1 inpainting мы сфокусировались на улучшение качестве модели генерации объектов. В Kandinsky 3.0 мы учили модель восстанавливать изображение по ее исходному описанию — из-за этого модель очень хорошо восстанавливает исходное изображение, но когда дело доходит до генерации другого объекта на месте старого, то модель может не справиться. Чтобы исправить эту проблему один из подходов это дообучение на масках с датасетов для задачи object detection (например, Paint by Example или SmartBrush). При использовании bounding box масок модель учится генерировать изображения четко по текстовому запросу, таким образом, избегая случаев, когда генерация не срабатывает. Чтобы модель не разучилась и в обычный inpainting, то мы сбалансировали наши сеты обучения — 50% масок приходят с bounding boxes, 50% случайных масок.
")
")
Поскольку в качестве текстовых запросов мы используем только имена классов, то модель может разучится генерировать по длинным запросам. Поэтому мы решили доразметить наш датасет с помощью LLaVA 1.5. Для этого, после выбора bounding box, который мы использовали в качестве маски, мы подавали crop изображения в LLaVA, чтобы получить текстовое описание изображения, которое дальше использовалось как текстовый запрос.
")
")
Также мы провели сравнение с другими моделями, чтобы проверить качество нашего нового метода inpainting-а. Для этого мы взяли датасет COCO и случайным образом отобрали из него 1000 изображений и один объект с каждого объекта, который мы перегенерировали. Далее на полученных картинках мы прогнали модель, обученную на датасете детекции YOLO-X, и посчитали её метрики качества детекции. Если детектор, обученный на реальных изображениях сможет задетектировать сгенерированный объект, то можно сделать вывод, что объект сгенерирован достаточно естественно. Ниже мы приводим метрики
Модель / Метрика |
AP50↑ |
AP small↑ |
AP large↑ |
SD |
0,276 |
0,033 |
0,253 |
SDXL |
0,272 |
0,032 |
0,245 |
SD2 |
0,238 |
0,032 |
0,205 |
Kandinsky 3.0 (Ours) |
0,290 |
0,028 |
0,275 |
Kandinsky 3.1 (Ours) |
0,306 |
0,027 |
0,296 |
Наша модель хорошо справляется с большими объектами и в целом ее качество при добавлении объектов намного лучше.
Kandinsky SuperRes
В новой версии Kandinsky 3.1 появилась возможность получать генерации изображений в разрешении 4K. Для этого была обучена диффузионная модель повышения разрешения KandiSuperRes.
За основу была взята архитектура Kandinsky 3.0, но с некоторыми модификациями.
Вместо латентной диффузии была реализована пиксельная диффузия, чтобы исключить потерю качества при кодировании и декодировании картинки автоэнкодером. Помимо этого, в ходе экспериментов было выявлено, что пиксельная диффузия сходится быстрее и лучше, чем латентная для этой задачи.
Вместо обычного Unet был реализован EfficientUnet подобно подходу, описанному в статье Imagen. В сравнении с U-Net Kandinsky 3.0, EfficientUnet потребляет меньше памяти и также имеет лучшую сходимость. Отличие в том, что вместо 3 Residual блоков на каждом понижении разрешения, в EfficientUnet используется большее количество блоков на низких разрешениях, и меньшее количество блоков на высоких. Также изменяется порядок выполнения свертки и downsampling/upsampling операций относительно исходного U-Net. Кроме этого, мы убрали обусловливание на текстовый промт, т.к. он не вносит вклад в генерации в высоком разрешение 4К. В итоге EfficientUnet KandiSuperRes содержит 413M параметров.
Во время обучения EfficientUnet предсказывает не уровень шума в данный момент времени t, как это обычно принято при обучении диффузионных моделей, а x_0 (т.е. исходную картинку), что позволило избежать проблем, связанных с изменением цвета сгенерированной SR картинки.
Обучение осуществлялось в 2 этапа — сначала модель училась на датасете Laion на 32 A100 в течении 1,570 тысяч шагов с размером батча 2 на разрешение из 256 в 1024. Затем модель училась на эстетичных сетах высокого разрешения, используемых при обучении Kandinsky 3.0, в течении 1,500 тысяч шагов. На втором этапе обучения было добавлено JPEG сжатие подобной той схеме, которая описана в статье Real-ESRGAN.
Модель KandiSuperRes позволяет работать с изображениями различного разрешения, однако основной целью являются генерации в высоком разрешении 4K. Т. к. модель KandiSuperRes обучалась на разрешение 256 → 1024, а на большем разрешение обучить не было возможности из-за переполнения памяти A100, для генерации в 4К использовался алгоритм MultiDiffusion, позволяющий генерировать панорамы. Суть алгоритма заключается в том, что изначально изображение делится на перекрывающиеся патчи, и затем на каждом шаге диффузии удаляется шум, а значения пикселей / латентов перекрывающихся областей усредняются. И таким образом, пройдя все шаги диффузии, мы получаем бесшовное изображение любого разрешения. В итоге на инференсе модель KandiSuperRes работает за 5 шагов, используя DPMSolverMultistepScheduler. Время инференса для генерации изображения в 4К занимает 13 секунд, а в 1К — 0,5 секунды.
В таблице ниже приведено сравнение KandiSuperRes с моделями Real-ESRGAN и Stable Diffusion x4 Upscaler по метрикам FID, SSIM, PSNR и L1 на датасетах Wikidata 5К, RealSR(V3) и Set14. Wikidata 5К содержит 5 тысяч изображений, собранных из википедии, в разрешении 1К. RealSR(V3) содержит 100 тестовых изображений в разрешениях 1K и 2K. Set14 содержит 14 изображений в низких разрешениях с JPEG артефактами. В итоге модель KandiSuperRes показала наилучшие результаты.
Сравнение моделей Real-ESRGAN, Stable Diffusion и KandiSuperRes:
Dataset |
Model |
FID↓ |
PSNR↑ |
SSIM↑ |
L1↓ |
Wikidata 5k |
Real-ESRGAN |
9.96 |
24.48 |
0.73 |
0.0428 |
Stable Diffusion |
3.04 |
25.05 |
0.67 |
0.0435 |
|
KandiSuperRes |
0.89💥 |
28.52💥 |
0.81💥 |
0.0257💥 |
|
RealSR(V3) |
Real-ESRGAN |
73.26 |
23.12 |
0.72 |
0.0610 |
Stable Diffusion |
47.79 |
24.85 |
0.67 |
0.0493 |
|
KandiSuperRes |
47.37💥 |
25.05💥 |
0.75💥 |
0.0462💥 |
|
Set14 |
Real-ESRGAN |
115.94 |
22.88 |
0.62 |
0.0561 |
Stable Diffusion |
76.32 |
23.60 |
0.57 |
0.0520 |
|
KandiSuperRes |
61.00💥 |
25.70💥 |
0.70💥 |
0.0390💥 |
На рисунке 1 приведены примеры генераций моделей KandiSuperRes, Stable Diffusion и Real-ESRGAN на разрешение 1024. На рисунке 2 приведены примеры генераций KandiSuperRes в разрешение 4К.
Код и веса KandiSuperRes выложены на Github и HuggingFace.


Маленькие версии модели (1B)
Чтобы сделать нашу модель более доступной для запуска и дообучения при малых вычислительных ресурсах мы решили обучить маленькую версию модели. Для нее мы взяли U-Net, содержащий 1 миллиард параметров, и текстовый энкодер от FLAN-T5 XL. Обучение происходило в течение 1-го миллиона итераций на датасете COYO 700m с размером батча 2048. Внизу представлены примеры генераций с помощью этой модели.


Вывод
В этой статье мы представили новую версию нашей диффузионной модели генерации изображений по тексту Kandinsky 3.1, которую мы сделали более эффективной с помощью современных методов дистилляции и дополнили новыми режимами работы, которых не было в версии Kandinsky 3.0 — возможностью редактирования изображений и переносом стиля. Дополнительно мы улучшили качество работы inpainting-а, метода повышения разрешения для перехода в пространство пикселей из пространства скрытых представлений, а также, помимо доступа к основной большой модели, мы предоставили пользователям возможность работы с версиями нашей модели с меньшим числом параметров, что гораздо удобнее для локального запуска и дообучения при малых ресурсах для своих целей и задач. Можно сказать, что наше основное достижение это то, что мы сделали творческую генерацию гораздо более удобной для пользователя, который теперь может полноценно использовать весь потенциал нашей модели.
Как и всегда, мы ценим открытые исследования и охотно делимся ими с вами, чему вновь стала примером данная статья. Мы предоставляем доступ к нашей модели, к её функциям, коду и обученным весам совершенно бесплатно для любого пользователя, стимулируя тем самым развитие области генеративного искусственного интеллекта. Однако, разумеется, следует помнить об ответственности каждого, кто решает использовать генерации изображений в своих целях. Мы настоятельно предостерегаем и выступаем против использования нашей модели в незаконных целях, которые могут послужить дезинформации, оскорблению, разжиганию ненависти и т. д. Мы уверены, что развитие искусственного интеллекта и непрерывный труд нашей команды направлены на мирное и благополучное созидание и улучшение качества труда и жизни наших пользователей.
Искусственный интеллект все больше входит в нашу жизнь и становится нашим полноценным помощником. Возможно, в ближайшее время модели генерации выйдут на совершенно иной уровень, комбинируя в себе возможности целых мультимедийных центров, оперирующих различными визуальными (и не только) модальностями. Наша команда активно вовлечена в подобные исследованиями, мы продолжаем держать руку на пульсе, следим за самыми последними новинками и продолжим радовать сообщество нашими достижениями. Шагайте и дальше в светлое и умное будущее за руку с технологиями и следите за нашими обновлениями!
Скоро все желающие смогут протестировать новые возможности нейросети. Как и предыдущие версии, модель будет бесплатной и доступной на разных поверхностях.
Авторы и их вклад
Модель Kandinsky 3.1 разработана командой Sber AI при партнёрской поддержке учёных из Института искусственного интеллекта AIRI на объединённых датасетах Sber AI и компании SberDevices.
Коллектив авторов: Владимир Архипкин, Андрей Филатов, Вячеслав Васильев, Анастасия Мальцева, Игорь Павлов, Михаил Шойтов, Юлия Агафонова, Николай Герасименко, Анастасия Лысенко, Илья Рябов, Саид Азизов, Антон Букашкин, Елизавета Дахова, Татьяна Никулина, Сергей Марков, Андрей Кузнецов и Денис Димитров.
Каналы авторов:
Контакты для коммуникации
По всем возникающим вопросам и предложениям по развитию модели, добавлению новых возможностей и сотрудничеству в части использования наших разработок можно писать мне или Андрею.
Полезные ссылки для пользования предыдущими версиями модели:
Telegram-bot (доступна генерация по тексту)
rudalle.ru (доступна генерация по тексту)
Github (доступен код модели генерации изображений и inpainting)
HuggingFace (доступны веса модели генерации изображений и inpainting)