Комментарии 0
...комментариев пока нет
OpenAI представила долгожданную GPT-4.5 (Orion)
Впечатления неоднозначные…
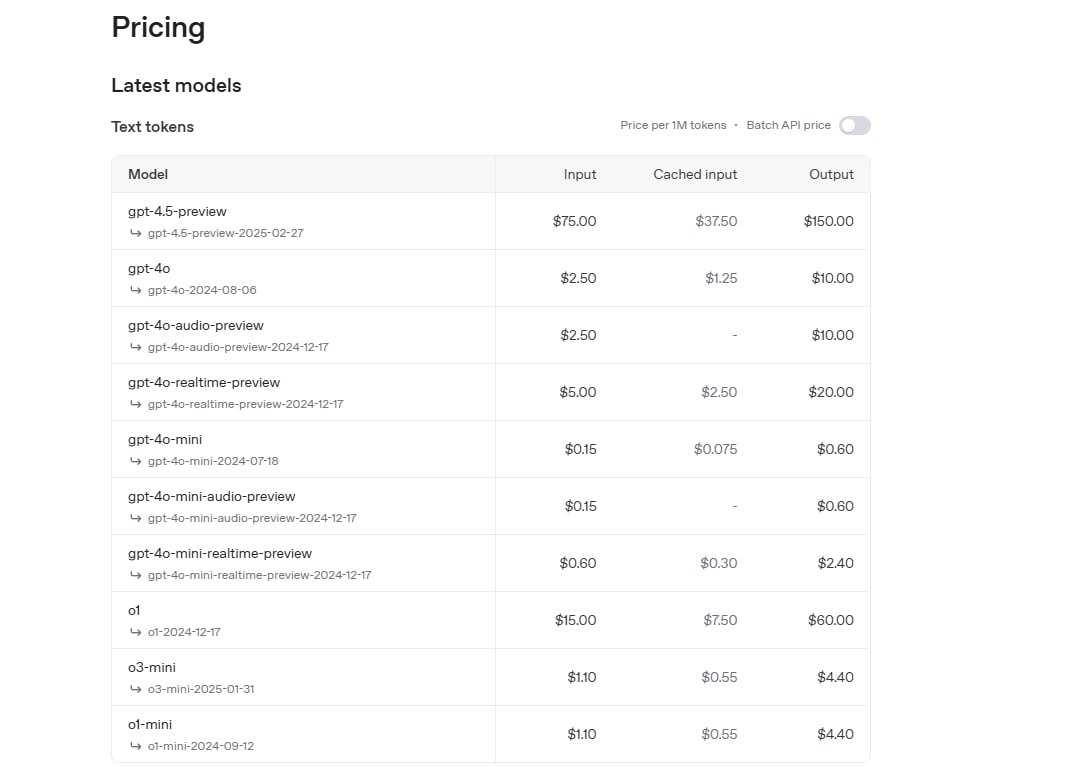
Первое, что сразу стоит отметить – это цена. Стоимость 1 млн выходных токенов достигла рекордных в индустрии 150 долларов vs $10 у GPT-4o, $60 у думающей o1 и всего $4.4 у o3-mini, а у конкурентов: Claude 3.7 Sonnet – $15, Qwen2.5 Max – $6.4, DeepSeek R1 – $2.19, Gemini 1.5 Pro – $5, Gemini 2.0 Flash всего $0.4.
Запредельная цена за входные токены – 75 баксов, тогда как у GPT-4o в 30 раз меньше – $2.5, o3-mini – $1.1, а o1 – $15, в сравнении с конкурентами GPT-4.5 сильно проигрывает: Claude 3.7 Sonnet – $3, Qwen2.5 Max – $1.6, DeepSeek R1 – $0.55, Gemini 1.5 Pro – $1.25, Gemini 2.0 Flash практически бесплатна - $0.1.
Отраслевой стандарт для высококачественных моделей составляет широкий диапазон от 0.5 до 3 баксов, но не $75, что, как минимум, в 30-50 раз (!) выше нормы.
Цена делает модель абсолютно бесполезной для любых видов коммерческого внедрения при любых типах задач.
Почему? Прирост производительности не скалируется (не растет пропорционально) в соответствии с невероятным ростом цены.
GPT-4.5 еще недоступна в публичном доступе, но мне удалось протестировать в среде для разработчиков.
Сразу отмечается критическая низкая скорость работы (так медленно не работает даже o1, которая в ТОПе антирейтинга по скорости работы) и отсутствие решительного прогресса в качестве генерации.
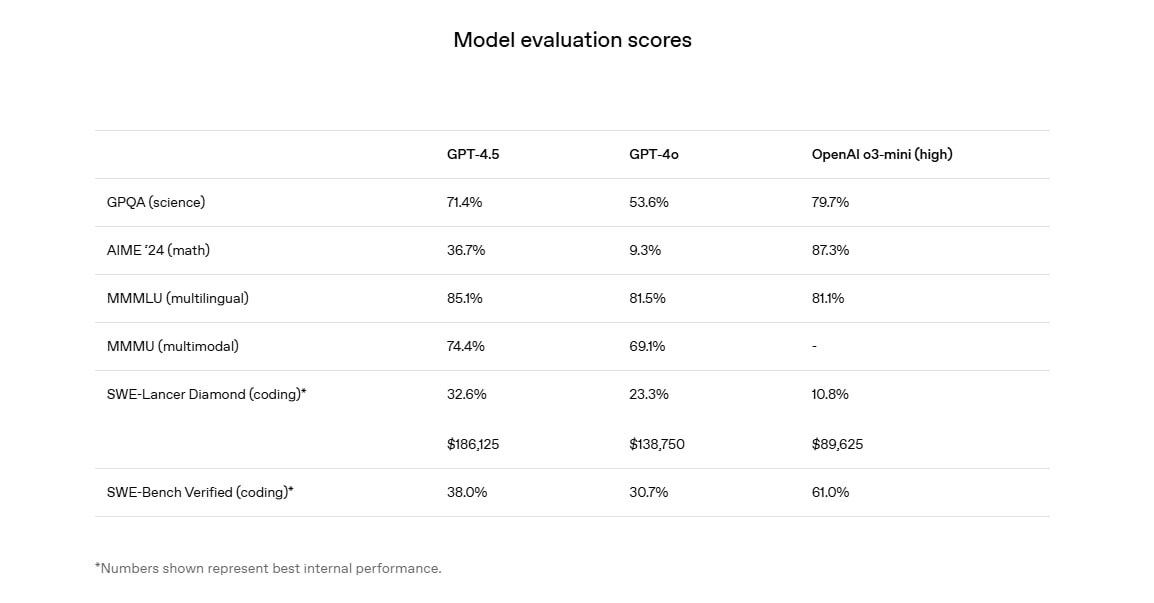
В целом, по беглому взгляду модель уверенно лучше, чем устаревшая на два года GPT-4o, но прогресс не такой очевидный в сравнении с Claude 3.7 Sonnet и весьма спорное и неоднозначное сравнение с Grok 3.
Сравнивать с DeepSeek R1, o3-mini и другими «думающими» моделями некорректно, т.к. они функционируют по разным принципам.
Сравнение GPT-4o с GPT-3.5 два года назад показывало решительное превосходство, а вот сравнение GPT-4.5 с GPT-4o уже не так ярко, особенно на фоне существующих моделей и прогресса у конкурентов.
По предварительным оценкам, среди «нерассуждающих» моделей, GPT-4.5 либо на первом месте, либо в группе лидеров около Claude 3.7 Sonnet, Grok 3 и Gemini 2.0 Pro в зависимости от конфигурации задачи.
Из первых впечатлений: GPT-4.5 более лаконичен (это не всегда плюс, скорее даже минус, если задача стоит докопаться до деталей) и более естественен (язык более похож на разговорный, что также спорное преимущество, т.к. цель LLM получить ответ или решить задачу, а не поговорить).
Как GPT-4.5 описывает OpenAI?
GPT-4.5 — пример масштабирования неконтролируемого обучения путем масштабирования вычислений и данных, а также инноваций в области архитектуры и оптимизации. Результатом является модель, которая обладает более широкими знаниями и более глубоким пониманием мира, что приводит к уменьшению галлюцинаций и большей надежности в широком спектре тем.
Другими словами, модель более «эрудированная», больше набита всякими данными и знаниями.
GPT-4.5 поддерживает генерацию текста, обработку изображений, загрузку файлов и инструмент холста для совместного редактирования, но не поддерживает мультимодальные функции, такие как голосовой режим, видео и совместное использование экрана в ChatGPT. Функционал пока урезан, доступа в сеть пока нет в среде разработчиков.
OpenAI заявляет, что GPT-4.5 значительно лучше понимает «человеческие эмоции» и намерения, интерпретирует тонкие сигналы или неявные ожидания с большей нюансировкой, т.е. лучше развит «эмоциональный интеллект», что приводит к более естественному общению.
Еще главное преимущество – повышение точности и снижение галлюцинаций. В тесте PersonQA (проверка на галлюцинации) точность ответов выросла с 28% (GPT-4o) и 55% (o1) до 78% у GPT-4.5, а частота галлюцинаций снизилась с 52% до 19%.
Сравнение с конкурентами показывает конкурентоспособность, но не абсолютное лидерство, а это означает, что опыт использования будут определять функционал, способность к тонкой настройке и стабильность результатов (снижение галлюцинаций).
Учитывая запредельную цену и низкую скорость работы, выбор неоднозначный. Продолжу тестировать.