Искуственный Интеллект и Продуктивность (AlekZ)
Мы кратко обсудим содержание недавней статьи “Полевые экспериментальные данные о влиянии искусственного интеллекта на производительность и качество труда работников сферы знаний” и затем приведем (реальный) диалог с ИИ (Microsoft Co-pilot), который мы попросили сделать аннотации (1) этого же самого документа и (2) текста Авантюриста “Деньги из воздуха или байка о 100 долларах и двери» . Хотя это и не является основной темой этого поста, в секции «Обсуждение» мы указываем на острую необходимость скорейшего создания собственных Российских LLM и чат-ботов только на российской (а не зарубежной) основе и, соответственно, тщательно отфильтрованной собственной базы текстов для их (LLM) тренировки.
Введение
«Концепция»/документ “Полевые экспериментальные данные о влиянии искусственного интеллекта на производительность и качество труда работников сферы знаний” представляет собой попытку измерить влияние ИИ на эффективность работы сотрудников реально существующего бизнеса. В процессе эксперимента большой группе сотрудников (758 человек) предлагалось решить реальные/реалистичные «творческие» проблемы связанные с их непосредственными обязанностями с использованием и без использования ИИ. Результаты для проблем, которые считались «в сфере компетенции используемой LLM» показали значительное увеличения продуктивности и качества решений, причем отчетливо видимым был эффект «выравнивания» - наибольший положительный эффект в качестве (+43%) был для наименее «способных» сотрудников, тогда как наиболее «способные» улучшили свои показатели в меньшей степени ( на ~ 17%). В области «за границей компетентности LLM» ИИ результат был обратным — сотрудники использовавшие ИИ показали результат в среднем 19% ниже («хуже») базовой линии. Хотя и оценены как «достаточно разумные», использованные в статье методология оценок и определения «границ компетенции ИИ» не являются целью данного поста, и поэтому не обсуждаются.
Общие результаты исследования в достаточной степени отражаются двумя графиками. Первый выглядит так:
По вертикали плотность вероятности распределения «качества» решений по шкале от 0 до 8. Синим — сотрудники не использовавшие ИИ, зеленым — использовавшие ИИ без дополнительного инструктажа по его использованию, красным- использовавшие ИИ и получившие инструктаж.
Второй график отражает интересную разницу в «мышления» ИИ и человека.
Распределение «похожести/однообразности» решений по шкале «похожести» от -0.1 до 0.5 (см. детали в статье)
Синий — контрольная группа, зеленый — человек +ИИ, красный — человек+ИИ+инструктаж, желтый — ИИ без человека.
Видно, что ИИ без человка генерирует значительно менее разнообразные решения (=во многом «похожие», «стандартные»), по сравнению с любыми другими комбинациями. При этом распределения для ИИ в комбинации с человеком выглядят как простая сумма распределения «чистого» ИИ и «чистого» человека.
Интересная небольшая деталь, отдельно исследованная в статье - «Сохранение информации» (человеком) после использования ИИ — сколько ответов из диалога с ИИ сохранялось в памяти человека и потом использовалось при решении задач.
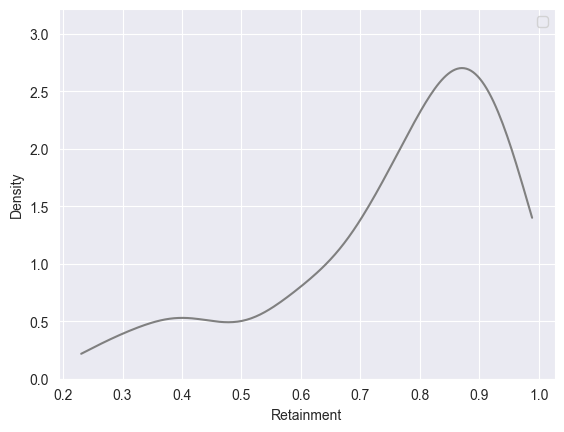
Плотность вероятности сохранения приобретенных с помощью ИИ информации по шкале от 0 до 1.0. Т.е подавляющее число сотрудников научилось чему-то полезному после общения с ИИ.
В целом результаты статьи несомненно интересные, указывающие на несомненную и значительную пользу применения ИИ в в реальном бизнесе, с достаточно детальным описанием методов и указанием на возможные ограничения. Статья, тем не менее могла бы дополнительно выиграть от менее пространного изложения (52 страницы А4 ).
Наши собственные эксперименты
1. Аннотация и диалог с MS Copilot - эксперимент над экспериментаторами
Диалог был на английском, переведен отдельно и несколько отредактирован (убраны несущественные элементы текста). MS Copilot попросили написать аннотацию на (оригинальный) текст, аннотация которого была приведена выше.
2. MS Copilot , текст Авантюриста «Деньги из воздуха или байка о 100 долларах и дверь https://glav.su/forum/threads/846491 (примечание — использовался перевод текста на английский Money Out of Thin Air or Tale About $100 and The Door ) . Машину попросили написать аннотацию и затем сравнить текст с реальным случаем круговой продажи/покупки пиццы одной пиццерией в США.
Обсуждение
Материал первого рассмотренного в этом посте документа (об увеличении производительности труда) представлен с двумя аннотациями - написанной человеком (мной) и машиной. Вы можете их сравнить (сами или попросить машину  ) При сравнении имейте в виду, что
) При сравнении имейте в виду, что
1. Любой человек имеет «свои» интересы, специфическое образование, политические и другие убеждения и поэтому выделяет не обязательно то, что выделили бы вы. То же касается и формы предоставления информации. То есть, как это ни парадоксально, написанная человеком аннотация написана скорее для автора, а не для вас.
2. В этом смысле, как автор, машина (LLM) представляет собой усредненного человека с усредненными интересами, убеждениями и образованием (об этом чуть ниже).Поэтому то, что машина «сообщает» вам на выходе, сообщается в усредненной форме и стиле, вероятно , с большей вероятностью подходящем для широкого использования «средним» пользователем, но не обязательно лично вам. Поэтому в ходе «дискуссии» с LLM о конкретном материале или теме можно (и нужно!) задавать вопросы и требовать дополнительной информации, чтобы «специализировать» «усредненный» ответ конкретно для ваших целей. Машина эту цель изначально не знает, но предполагает «среднюю» по своей выборке - примерно «не читал, но могу сообщить о чем это».
Теперь о том, c чем вы имеете дело в лице машины (LLM).
Конкретная современная LLМ («модель» в дальнейшем) тренирована на большом объеме материалов из общения людей в емейлах или в твиттере,или публикаций в «ведущих» западных журналах, или обсуждений этих публикаций и тп или любой комбинации вышеперечисленного. Кто и как общается в этих материалах? Да. Именно. Например, многие советские иммигранты в западные страны обращают внимание, что люди вокруг них как правило никогда не выдают информацию добровольно. Т.е. если ты уже заранее не знаешь, что тебе нужно, то подсказку не получишь. Можно спорить, почему это так — от «уважения» к праву личности разбить себе лоб, от желания не давать преимуществ конкуренту или это пережиток времен, когда чтобы получить какие-то профессиональные знания нужно было заплатить годами работы «ученикам» мастера — неважно. Важно, что именно так и ведет себя модель в разговоре с вами.
Кроме того, точно также как типичные жители запада в разговоре с незнакомыми людьми**, она всеми силами стремится избегать «спорных» вопросов и тематик, обходить острые углы и выглядеть дружелюбным и неконфликтным.
Не следует также забывать, что этот «средний» человек, которого имитирует модель, создан даже не из реальных и уже не вполне полноценных западных людей, а того, что от него осталось в искаженных и глубоко цензурированных ультра либеральной и западной пропагандой текстов. Как например в Твиттере — который «Не бизнес, а оружие» https://rwmalonemd.substack.com/p/twitter-is-a-weapon-not-a-business . Что разрешено или не разрешено к публикации в «независимой и демократической» прессе на западе мне здесь даже объяснять не нужно. Несмотря на «естественную» «пре-цензуру», тексты подвергаются дополнительной модерации при их обработке непосредственно для тренировки модели, и затем — дополнительной цензуре (alignment rules) при работе модели с пользователем.
Что с этим делать?
По наводке тов.Wig https://aftershock.news/?q=node/1348594 я протестировал несколько полностью локальных моделей в режиме работы с локальными документами. Да, при использовании нецезурированных моделей результаты получаются лучше — например, все такие модели справляются с известным классическим вопросом «как убить процесс в Линуксе?» на который обычные модели отвечали длинной лекции об аморальности таких желаний (ну, машина лучше понимает душу другой машины ). Такие модели способны создавать приличные аннотации на статьи на политические темы, и позволяют себе вот такие утверждения — которых вы не добьетесь от «официальных» моделей.
Примеры:
Тем не менее, общая тенденция избегать конфронтации с клиентом, уклонение от прямых ответов на «острые» политические темы — или склонность смотреть на мир, как ангел смотрит на джунгли из райских садов, остается. Что и не удивительно, учитывая на каких материалах и на какой «культуре» (и против какой культуры) эти модели были тренированы.
Поэтому России необходимо иметь свои модели (и желательно ограничить доступ к западным) -это я зря, наверное .. . ИИ уже стал эффективным оружием и необходимо иметь свое. При этом необходимо иметь в виду, что использование для тренировки всех без фильтрации «своих» материалов из тех же ВК и ЖЖ и тп принесет скорее вред чем пользу — практически все публичные форумы в высокой степени засраны если не теми же западными ИИ чат-ботами, то хохлами и сотрудниками военизированных формирований типа 17 Brigade и многими подобными военно-психологическими отделениями действующих западных армий.
Примечания
** а может быть стоит "представиться" машине перед диалогом - описать кратко вашу роль в диалоге. Это нормальная ситуация в диалогах, на которых модели тренируют, и их структура в некотором смысле в модели присутствует в весах, правда же?